
Large Language Models for Explainable Link Prediction (Project Group)
Note: For more information about the project group, and its prerequisites, please refer to the project groups overview page.
Content
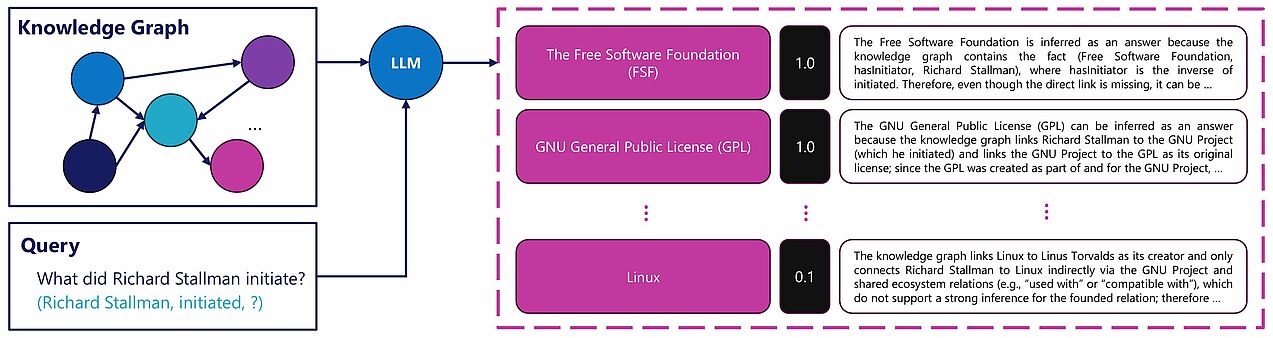
Knowledge Graphs (KGs) represent data as a network of entities and their relationships. For example, in a triple-based knowledge graph, a fact is represented as a subject–predicate–object triple, such as (Paderborn, located_in, North Rhine-Westphalia). However, real-world KGs are inevitably incomplete, as it is difficult or even impossible to capture all pieces of knowledge related to a given concept. Consequently, the task of link prediction aims to infer missing or potential relationships between entities in a KG based on existing knowledge. This task is commonly formulated as a ranking problem: given a query of the form (Paderborn, located_in, ?) or (?, located_in, North Rhine-Westphalia), the model scores all candidate entities for the missing position and ranks them according to their likelihood.
In recent years, there has been an enormous amount of research on link prediction, with a particular focus on embedding-based methods. However, these methods often lack interpretability, making it challenging to understand the reasoning behind their predictions. Building on the promising performance of Large Language Models (LLMs) in complex reasoning tasks such as mathematical problem solving and code generation, and on their self-explanatory nature, a recent line of research has begun to investigate the potential of LLMs for reasoning over KGs [1]. The approaches taken in these studies vary considerably, reflecting different design choices in how graph structures are represented and how they are provided to LLMs as context. For instance, some works verbalize (sub)graphs and rely on the zero-shot reasoning capabilities of LLMs through direct prompting [2, 3]. Others leverage reinforcement learning [4, 5], while a few use LLMs as rule miners [6].
Although LLMs have shown promising results on some basic tasks, their reasoning abilities for link prediction remain an open problem, particularly due to the large scale of knowledge graphs and the limited context windows of LLMs. Furthermore, several aspects remain underexplored in the current literature. For example, many existing works reformulate and simplify link prediction as a classification task that determines whether a link exists between two entities [7, 8]. In addition, many studies reporting strong performance rely heavily on textual information associated with entities and relations in the KG, rather than purely reasoning over the graph structure. Recently, some studies, most notably [5], have attempted to address these limitations by ignoring textual attributes and reformulating the task in a more practical manner. However, this line of research focuses primarily on temporal graphs, leaving the performance of LLMs on static KGs largely unexplored.
This project group aims to further investigate the capabilities of LLMs for link prediction on static knowledge graphs, with a primary focus on explainability. In addition to evaluating existing methods on standard benchmarks and exploring novel ideas, we will study how effectively LLMs can generate explanations for their predictions. Depending on the number of participants and their interests, we may also explore related aspects of this topic, such as developing more realistic benchmarks or studying user needs for explanations.
Requirements
- Solid programming skills in Python
- A habit of documenting and commenting code for clarity and collaboration
- Willingness to develop skills in reading scientific papers, reproducing experiments, and writing technical reports
- Openness to learning new concepts (e.g., Knowledge Graphs, Large Language Models, Machine Learning) and tools (e.g., PyTorch, HuggingFace, LangChain)
- Ability to spend approximately 20 hours per week on the project (2 × 10 ECTS)
Note: Students are encouraged to take the Explainable Artificial Intelligence course offered in the next summer semester, as it closely aligns with the project’s focus on explainability.
Contact
Slides
You can access the slides from the introductory presentation using this link.
Gallery
Related Work
- [1] Bahare Fatemi, Jonathan Halcrow, and Bryan Perozzi. Talk like a graph: Encoding graphs for large language models. In ICLR. OpenReview.net, 2024.
- [2] Xiaoxin He, Yijun Tian, Yifei Sun, Nitesh V. Chawla, Thomas Laurent, Yann LeCun, Xavier Bresson, and Bryan Hooi. G-retriever: Retrieval-augmented generation for textual graph understanding and question answering. In NeurIPS, 2024.
- [3] Rui Yang, Jiahao Zhu, Jianping Man, Li Fang, and Yi Zhou. Enhancing text-based knowledge graph completion with zero-shot large language models: A focus on semantic enhancement. Knowl. Based Syst., 300:112155, 2024.
- [4] Xiaojun Guo, Ang Li, Yifei Wang, Stefanie Jegelka, and Yisen Wang. G1: teaching llms to reason on graphs with reinforcement learning. CoRR, abs/2505.18499, 2025.
- [5] Zifeng Ding, Shenyang Huang, Zeyu Cao, Emma Kondrup, Zachary Yang, Xingyue Huang, Yuan Sui, Zhangdie Yuan, Yuqicheng Zhu, Xianglong Hu, Yuan He, Farimah Poursafaei, Michael M. Bronstein, and Andreas Vlachos. Self-exploring language models for explainable link forecasting on temporal graphs via reinforcement learning. CoRR, abs/2509.00975, 2025.
- [6] Linhao Luo, Jiaxin Ju, Bo Xiong, Yuan-Fang Li, Gholamreza Haffari, and Shirui Pan. Chatrule: Mining logical rules with large language models for knowledge graph reasoning. In PAKDD (2), volume 15871 of Lecture Notes in Computer Science, pages 314–325. Springer, 2025.
- [7] Dong Shu, Tianle Chen, Mingyu Jin, Chong Zhang, Mengnan Du, and Yongfeng Zhang. Knowledge graph large language model (KG-LLM) for link prediction. In ACML, volume 260 of Proceedings of Machine Learning Research, pages 143–158. PMLR, 2024.
- [8] Liang Yao, Jiazhen Peng, Chengsheng Mao, and Yuan Luo. Exploring large language models for knowledge graph completion. In ICASSP, pages 1–5. IEEE, 2025.
FAQ
Students from both Computer Science and Computer Engineering majors are welcome. Please refer to the requirements listed in the description above for more details.
The project group is worth 2 × 10 ECTS, and students are therefore expected to spend approximately 20 hours per week on the project. You may distribute this time in the way that best suits your schedule.
Collaborative development will be managed via Git, and students are expected to make regular commits and pushes throughout the week. In addition, each student is required to submit a brief weekly report summarizing their progress.
In the first weeks, we will mainly focus on the prerequisites and short presentations. Fundamental topics (e.g., Git, Scrum) will be introduced, and students will be asked to learn and briefly present them to ensure that everyone is familiar with the basic tools and workflows.
The project group strongly emphasizes teamwork. Depending on the size of the group, students may be divided into smaller teams, with each team assigned tasks that best match their interests and skills.
While prior experience with Large Language Models or Knowledge Graphs is appreciated, it is not required. The project group is designed to allow students to learn the necessary concepts during the project, focusing only on what is needed. As mentioned above, we encourage students to take the Explainable Artificial Intelligence course if they have not done so already. The Foundations of Knowledge Graphs course may also be beneficial for those who wish to gain deeper insight into knowledge graphs.