
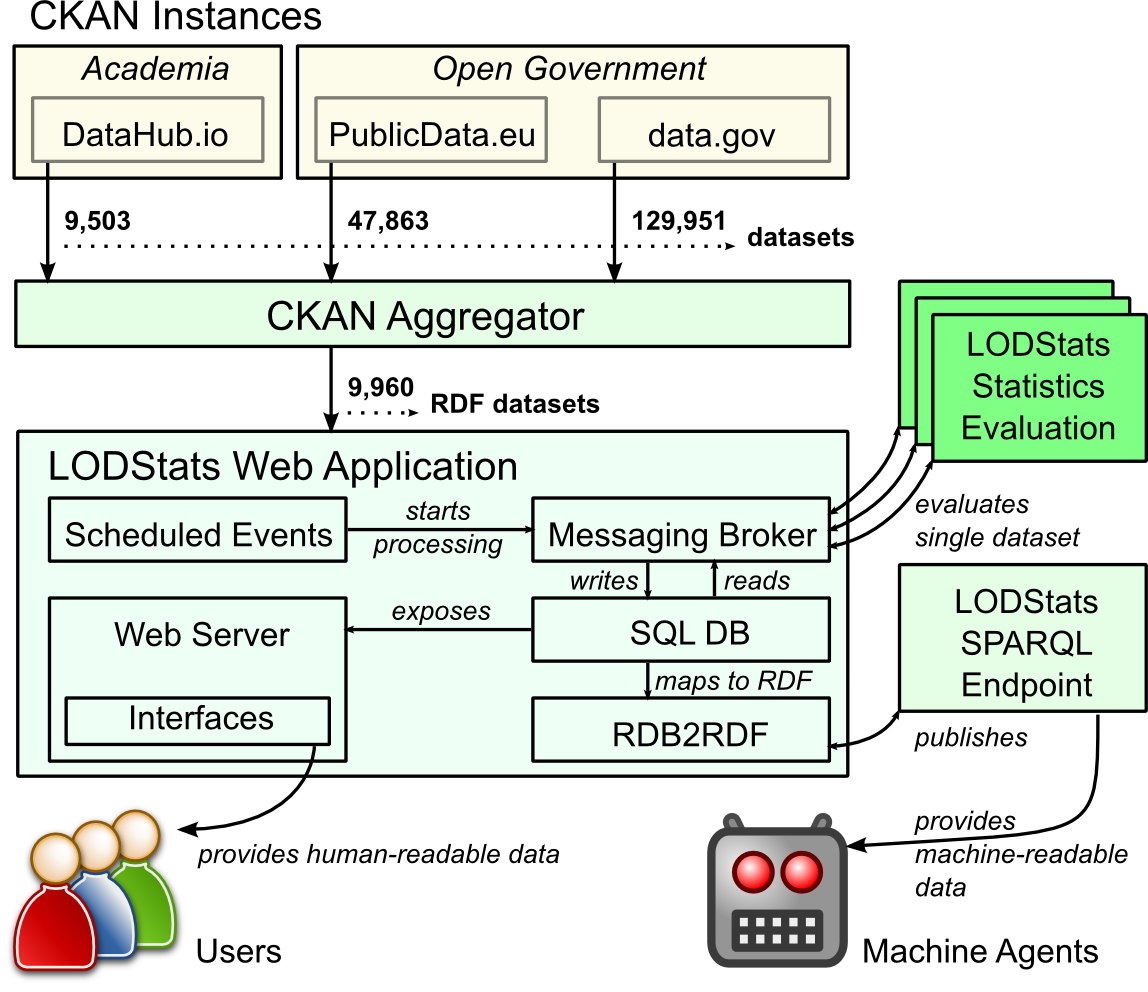
In this blogpost we highlight <link https: github.com dice-group ckan-aggregator-py>ckan-aggregator-py, a Python library, which crawls <link https: ckan.org>CKAN metadata stores and can specifically filter RDF datasets. The library was developed as a helper for <link http: lodstats.aksw.org>LODStats application and was used to scrape RDF datasets and load them into the application for further processing (see figure 1). At the moment of writing the following CKAN stores are available for crawling using ckan-aggregator-py:
- <link http: data.gov>data.gov
- <link http: datahub.io>datahub.io
- <link http: open.canada.ca data en>opencanada
- <link http: publicdata.eu>publicdata.eu
- <link http: opendata.leipzig.de>opendata.leipzig.de
To install ckan-aggregator-py, simply execute the following commands (you may need to install <link https: virtualenvwrapper.readthedocs.io>virtualenvwrapper before proceeding):
$ mkvirtualenv aggregator-py
$ cdvirtualenv
$ mkdir src && cd src
$ git clone git@github.com:dice-group/ckan-aggregator-py.git && cd ckan-aggregator-py
$ pip install -r requirements.txt
This will create Python virtual environment called aggregator-py and clone ckan-aggregator-py src/ckan-aggregator-py in the created virtual env.
Now, run init.sh script to create folders for storing crawled data:
$ ./init.sh
By default ckan-aggregator-py can access CKAN without the API key. If you want to have more requests to a CKAN endpoint than an average user, it is a good idea to register on a CKAN instance and use an API key. To configure an API key simply override __init__.py with __init__.py-example-key from the same folder. For example, for datahub.io:
$ cp ckanaggregatorpy/datahubio/__init__.py-example-key ckanaggregatorpy/datahubio/__init__.py
Then edit the new __init__.py file in your favorite editor.
We are now ready to crawl a CKAN datastore. Here we demonstrate usage of ckan-aggregator-py for scraping the Open Leipzig data portal. For this example, we implemented open-leipzig.py script. To run the example simply execute the script:
$ python open-leipzig.py
You will see output showing the number of packages in the CKAN instance, the number of RDF packages and example metadata of a single RDF package.
Leipzig Open Data portal contains 579 packages.
Updating the local package cache
...
...
...
Leipzig Open Data portal contains 85 packages, which contain RDF data
Showing metadata from CKAN for the first RDF package
{u'author': u'Amt f\xfcr Statistik und Wahlen',
u'author_email': u'mailto:statistik-wahlen@leipzig.de',u'ckan_url': u'https://opendata.leipzig.de//dataset/allgemeinbildende-schulen',u'ckan_url': u'https://opendata.leipzig.de//dataset/allgemeinbildende-schulen',u'ckan_url': u'https://opendata.leipzig.de//dataset/allgemeinbildende-schulen',u'creator_user_id': u'2046a73a-e0c2-42b6-bd8c-8da6ad8c552d',
...
...
...
u'version': None}
The metadata of the filtered packages can be further processed, transformed and loaded into applications (e.g. LODStats).

{kind=link}