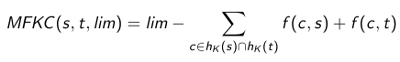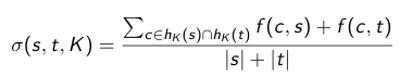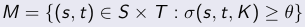The Acronym MFKC means Most Frequent K Characters and was defined by Seker et al. (2014) for approximate string matching. This measure can compute a pair of strings rapidly, where the main characteristic is represented as hk(s), being a hash of the K most frequent characters of s sorted by frequency.
- example 1 (fig.1)
- The MFKC measure can be expressed as distance (fig.2)
- A example of its use is (fig.3)
- In order to use it as a similarity metric, the functions become as follows (fig.4 + fig.5)
- The aim of our work is to devise an efficient approach to compute the mapping M (fig.6)
For this we provide a sequence of filters that allow comparisons to be discarded when executing bounded similarity computations without losing recall. Therewith, we can reduce the runtime of bounded similarity computations by approximately 70%. Our experiments with a single-threaded, a parallel and a GPU implementation of our filters suggest that our approach scales well even when dealing with millions of potential comparisons.
The three filters work in sequence in the following manner (fig.7)
The experimental setup was:
- Datasets: DBpedia, LinkedGeoData and Yago
- Hardware: Intel Core i7 2.40 GHz (8 CPU cores), 8 GB RAM
- Metrics: Runtime, precision, recall, F-score
In this work, we defined a similarity-based most frequent K character measure, which is a time-efficient extension of the naïve algorithm using 3 filters. The approach was evaluated with respect to runtime and F-score. A parallel implementation works well on problems with more than 105 number of comparisons, which is given by the product of the sizes of Ds and Dt. In the future, the algorithm will be integrated into the LIMES framework.
- Contact: Andre Valdestilhas, Tommaso Soru, Axel-Cyrille Ngonga Ngomo
- valdestilhas@informatik.uni-leipzig.de
- tsoru@informatik.uni-leipzig.de
- axel.ngonga@upb.de
- Github repository: https://github.com/dice-group/MFKC
- Paper: http://disi.unitn.it/~pavel/om2017/papers/om2017_Tpaper1.pdf
- Presented at: ISWC 2017 inside the Ontology Matching workshop.
- Presentation slides: https://www.slideshare.net/hobbit_project/highperformance-approach-to-string-similarity-using-most-frequent-k-characters