
Palmetto has been developed for the topic modeling community and it can be used to calculate the coherence of a given word set. Its idea is straightforward: it uses a local Lucene index to get co-occurrence counts of the words of the given word set inside a reference corpus and uses them to calculate a coherence value.
There are different coherences that have been defined in the area of topic modeling. The most common coherences (C_UCI [1], C_UMass [2], C_NPMI [3], C_A [3], C_P [4] and C_V [4]) as well as more than 200.000 other coherences can be calculated easily using Palmetto.
In this blog post, we want to briefly explain the different ways in which Palmetto can be used and how it can be set up. Please note that in-depth explanations can be found online in the <link https: github.com dice-group palmetto wiki>wiki of the Palmetto project.
Using the web service
The easiest way to calculate a coherence value is the usage of our web service. Requesting the coherence for a word set can be done using the URL of the form
palmetto.aksw.org/palmetto-webapp/service/<coherence>;
where <words> are the space separated words and <coherence> is the name of the coherence. At present, the following values ca, cp, cv, npmi, uci or umass can be used. The response contains the floating point value as plain text.
Thanks to Ivan Ermilov, there is a Python client available at <link https: github.com earthquakesan palmetto-py>github.com/earthquakesan/palmetto-py
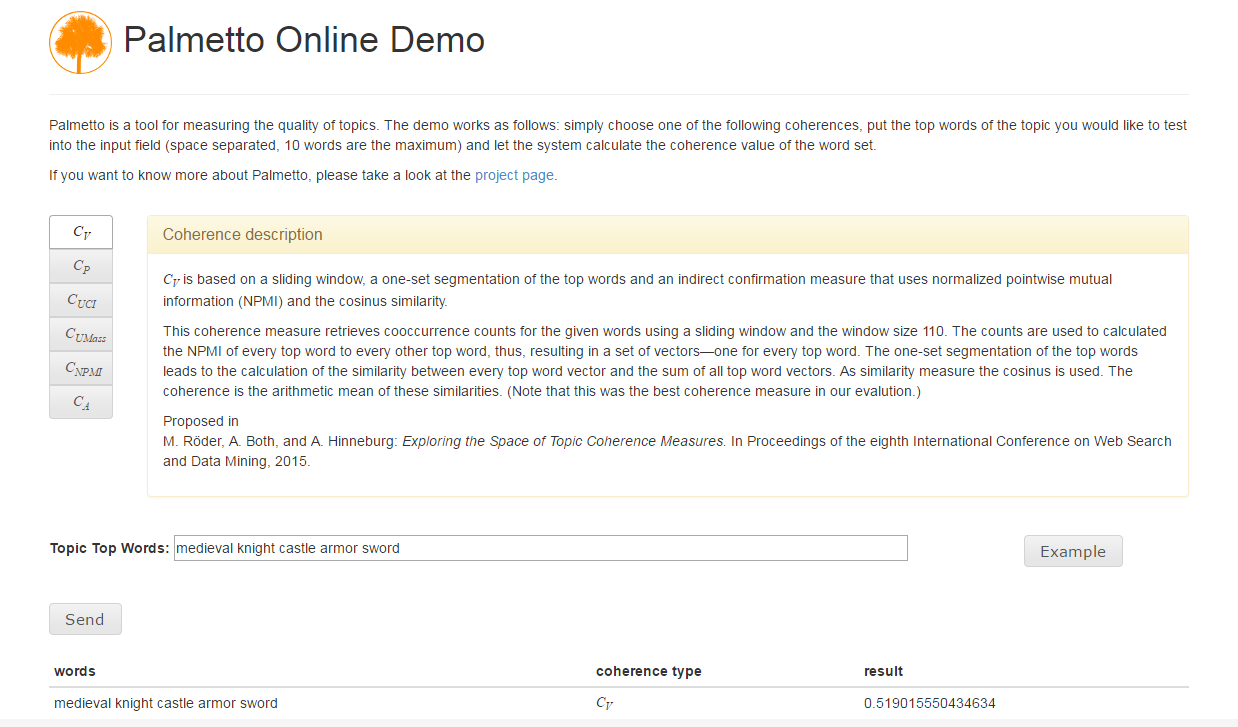
The service also offers a demo at <link http: palmetto.aksw.org palmetto-webapp>palmetto.aksw.org/palmetto-webapp/. The web service uses the Wikipedia as reference corpus. However, when downloading Palmetto, other corpora can be used as well.
Setting up the web service
The easiest way to set up Palmetto as an own local web service, is to use <link https: www.docker.com>Docker and to run the following two commands from the webApp directory of the Palmetto project.
docker build -t palmetto .
docker run -p 7777:8080 -d -m 4G -v /path/to/indexes/:/usr/src/indexes/:ro palmetto
Following this there is a Tomcat listening on port 7777. Note that the Lucene index used by the web service can be defined with /path/to/indexes. If the volume is not mounted, a wikipedia index will be used as default.
Using Palmetto as program
After downloading the source code, Palmetto can also be executed as a local program. From the palmetto directory, it can be built with
mvn clean compile assembly:single
and executed with the
java -jar target/palmetto-0.1.2-SNAPSHOT-jar-with-dependencies.jar <some-path>/wikipedia_bd <coherence> <topics-file>
command. Note that <some-path>/wikipedia_bd should be replaced with the path to the index, <coherence> is one of the 6 coherence values (C_A, C_P, C_V, NPMI, UCI or UMass) and <topics-file> defines a file that contains the word sets (one set per line; single words separated with a space).
Using Palmetto as library
Java programs can make use of Palmetto as a library enabling access to more than 200.000 different coherences. However, this requires diving into the source code of Palmetto which is not the focus of this article. (See <link https: github.com dice-group palmetto wiki>wiki article for further information on this topic).
Creating a new index
Normally, the english wikipedia is a good reference for calculating coherences for english word sets because it represents a broad, general knowledge. However, wikipedia is not exhaustive and Palmetto can be used with other reference corpora as well. Therefore, it can be necessary to generate a new index for a different language or for another, specialised corpus.
For Java developers, Palmetto offers the possibility to create new Lucene indexes. The details of that can be found in the <link https: github.com dice-group palmetto wiki how-to-create-a-new-index>Palmetto wiki where all the information presented in this blog post is explained in detail.
[1] D. Newman, J. H. Lau, K. Grieser, and T. Baldwin: Automatic evaluation of topic coherence. In Human Language Technologies: The 2010 Annual Conference of the North American Chapter of the Association for Computational Linguistics, pages 100-108. Association for Computational Linguistics, 2010.
[2] D. Mimno, H. M. Wallach, E. Talley, M. Leenders, and A. McCallum: Optimizing semantic coherence in topic models. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, pages 262-272. Association for Computational Linguistics, 2011.
[3] N. Aletras and M. Stevenson: Evaluating topic coherence using distributional semantics. In Proceedings of the 10th International Conference on Computational Semantics (IWCS'13) Long Papers, pages 13-22, 2013.
[4] M. Röder, A. Both, and A. Hinneburg: Exploring the Space of Topic Coherence Measures. In Proceedings of the eighth International Conference on Web Search and Data Mining, 2015.

{kind=link}
{kind=link}