
Research
The CSS Group does research on natural language processing, with a focus on topics related to computational argumentation and computational sociolinguistics. Recently, we also increasingly study educational and explainable artificial intelligence. Past research tackled text mining processes in general. Details are given in the following.
Computational Argumentation (CA)
Computational argumentation deals with the computational analysis and synthesis of natural language arguments and argumentation, usually in an empirical data-driven manner. Computational argumentation research that members of the CSS Group have particularly contributed to includes the following. Many of the outcomes of the group are or will be demonstrated in the argument search engine args.me.
In our argument generation research, we focus on understanding the core of an argument by inferring its conclusion (ACL 2020), as well as extracting snippets representing the most important claim and the reason behind (SIGIR 2020). We also study how to encode beliefs into arguments (EACL 2021), how to summarize a long argument down to its conclusion (ACL Findings 2021a), and how to undermine arguments with counter-arguments (ACL Findings 2021b).
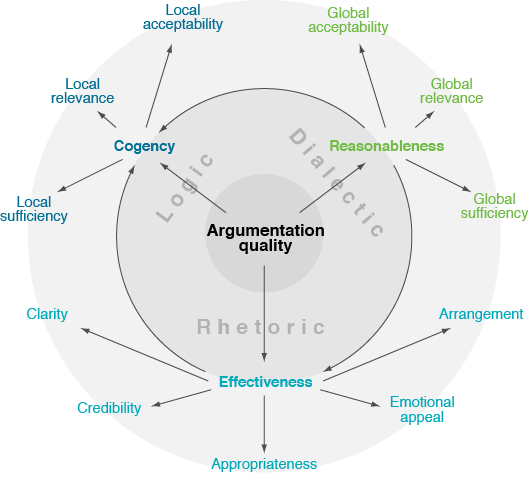
Starting from a literature survey, we defined a taxonomy of argumentation quality (EACL 2017), followed by an empirical comparison of theory and practice (ACL 2017). We developed computational approaches to assess specific quality dimensions, such as a machine learning regressor that uses argument mining for argumentation-related essay scoring (COLING 2016) and a PageRank adaptation for argument relevance (EACL 2017). Further, we developed a new notion of argument quality (CoNLL 2018) and assessed it for the different audience (ACL 2020). Recently, we have started to study what can be learnt about quality from argument revisions (EACL 2021).
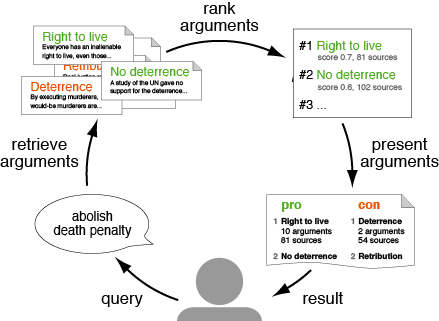
With args.me, we introduced the first search engine for arguments on the web (ArgMining 2017). The mentioned assessment of argument relevance (EACL 2017) may be used for ranking found arguments. Moreover, we developed a computational approach to retrieve counterarguments to arguments based on their simultaneous similarity and dissimilarity (ACL 2018).
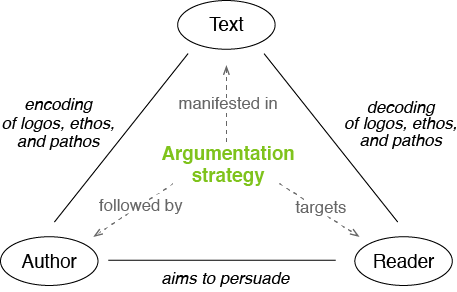
We have studied argumentation strategies based on a news editorial corpus with fine-grained evidence annotations (COLING 2016), we trained a classifier and used it to find topic-specific evidence patterns (EMNLP 2017). We modeled and empirically studied the synthesis process of authors following rhetorical strategies (COLING 2018), and we analyzed deliberative strategies in dialogical argumentation on Wikipedia talk pages (ACL 2018).
We also developed computational models of the sequential flow of review overall argumentation (COLING 2014) based on an annotated corpus (CICLing 2014). Mapping a text into the feature space of overall structures, flows predict its sentiment robust across domains (EMNLP 2015). Later, we generalized the flow model to other text genres and prediction tasks (ACM TOIT 2017), and we presented a new tree kernel-based approach to capture sequential and hierarchical overall argumentation at the same time (EMNLP 2017).
Other recent research topics include argument mining (NAACL 2016, ArgMining 2017), argument reasoning comprehension (NAACL 2018, SemEval 2018), ad-hominem fallacies (NAACL 2018), framing (EMNLP-IJCNLP 2019), and graph-based argument analyses (AAAI 2020, ACL 2021),
Computational Sociolinguistics (CSL)
Computational Sociolinguistics, as a subfield of computational social science, investigates research questions from the social sciences through empirical analyses of natural language data. Input data includes, but is not limited to, social media text, online activities, and socio-cultural key indicators. The focus is often on insights into social phenomena and dynamics rather than the technologies behind. The CSS group is doing computational sociolinguistics research on the following topics, partly in the context of the research program Digital Future.
Social bias can emerge from pre-existing beliefs about the characteristics of group members of any social group, often leading to prejudices and discrimination. Language can be a major factor in carrying and reinforcing those biases, causing NLP models that learn from it through texts to inherit those biases. Triggered by our project on bias in AI models, our research focuses on analyzing the bias in texts to understand the possible influence on downstream systems. More information can be found in our paper (ArgMining 2020). We are currently adding to this research by evaluating possible relations between social and political bias, as well as taking a closer at the methods that are widely used to detect biases in NLP systems (IJCAI 2021).
Media plays an important role in shaping public opinion. Biased media can influence people in undesirable directions and hence should be unmasked as such. To solve this problem with NLP techniques, we developed machine learning models to analysis the media bias. Especially, we focused on (1) learning about the relation between sentence-level and article-level bias (EMNLP Findings 2020), and (2) studying at what granularity level and how sequential patterns media bias is manifested (NLP+CSS 2020).
Regarding bias mitigation, we studied the task of “flipping” the bias of news articles: Given an article with a political bias (left or right), generate an article with the same topic but opposite bias. We created a corpus with bias-labelled articles from allsides.com. As a first step, we analyze the corpus and discuss intrinsic characteristics of bias. They point to the main challenges of bias flipping, which in turn lead to a specific setting in the generation process. We applied an autoencoder incorporating information from an article’s content to learn how to automatically flip the bias. More about this research can be found in our paper (INLG 2018).
Crowdworking is one phenomenon of the digitization of the society. Online platforms provide connections between requesters of tasks and workers who solve the tasks in an anonymous and distant manner. However, the quality of crowdworking is affected by communication problems in the task design, operation, and evaluation. To learn about the workers' side, we compared existing research on problems in crowdworking with complaints mined from a workers' online discussion forum (COLING 2020). The findings from this study form the basis for our research on how to improve crowdsourcing.
For many controversial topics in life and politics, people disagree on what is the right stance towards them, be it the need for feminism, the influence of religion, or the assassination of dictators. Stance is affected by the subjective assessment and weighting of pro and con arguments on the diverse aspects of a topic. Building stance in a self-determined manner is getting harder and harder in times of fake news and alternative facts, due to the unclear reliability of many sources and their bias in stance and covered aspects.
We are analyzing how a self-determined opinion formation can be supported through technologies such as the argument search engine args.me. More details follow soon.
Educational and Explainable Artificial Intelligence
Educational applications of natural language processing and other AI techniques include the computational support of writing studying learner-specific characteristics. Explainability expresses the desire to make a system’s behavior intelligible and thus controllable by humans. The CSS group is investigating respective topics more and more deeply, with a focus on the analysis and generation of natural language explanations. The following topics are in the focus in this regard.
We study the generation of used-adapted explanations, among others, in the context of our project in the CRC 901 "On-the-Fly Computing". Groundwork for explanations that adapt to the language of the user includes the modification of stylistic bias (INLG 2018), the generation of specific information (ACL 2020), and the encoding of beliefs into generated text (EACL 2021).
In the context of our research project ArgSchool, we study how to support learning to write texts through computational methods that provide developmental feedback. These methods assess and explain which aspects of a text are good, which need to be improved, and how to improve them, adapted to the student’s learning stage. More information will follow in the next months.
In the first of our projects within TRR 318 "Constructing Explainability", we study the pragmatic goal of all explaining processes: to be successful — that is, for the explanation to achieve the intended form of understanding (enabling, comprehension) of the given explanandum on the explainee's side. In particular, we investigate the question as to what characteristics successful explaining processes share in general, and what is specific to a given context or setting. Details on this topic will follow soon.
In the second of our projects within TRR 318 "Constructing Explainability", we study the metaphorical space established by different metaphors for one and the same concept. We seek to understand how metaphors foster understanding through highlighting and hiding, anw we aim to establish knowledge about when and how metaphors are used and adapted in explanatory dialogues. Details on this topic will follow soon.
Text Mining
Text mining deals with the automatic or semi-automatic discovery of new, previously unknown information of high quality from large numbers of unstructured texts. The types of information to be inferred from the texts are usually specified beforehand, i.e., text mining tackles given tasks. Text mining research that members of the CSS group have particularly contributed to includes the following.
We have developed a method that creates a text analysis pipeline ad-hoc in near-zero time for a specified information need along with a quality prioritization using partial order planning and greedy-best first search (CICLing 2013). In addition, we can automatically equip any such pipeline with an assumption-based truth maintenance system that systematically ensures that each algorithm in a pipeline analyzes only potentially relevant portions of text (CIKM 2013).
We developed a process to optimize the run-time efficiency of any text analysis pipeline (CIKM 2011). Based on the assumption-based truth maintenance system mentioned above, we found the theoretically optimal pipeline schedule using dynamic programming (COLING 2012). It depends on the run-time and found information of each employed text analysis algorithm. These values are not known beforehand, which is why an informed best-first search scheduling approach is more preferable in practice (LNCS 9383). In case the input texts to be process are heterogenous, an adaptive scheduling is needed, which we have realized with self-supervised online learning (IJCNLP 2013).