
Completed research projects of the High-Performance IT Systems group
The high-performance IT Systems group has been involved with numerous research projects, which are listed below. An overview of our current research projects can be found here.
HighPerMeshes – Domain-specific programming and target architecture aware compiler infrastructure for algorithms on unstructured grids

The goal of the project HighPerMeshes is to develop a practically usable domain-specific framework for the efficient, parallel and scaling implementation of iterative algorithms on unstructured grids. Simulation software in the time domain, that falls into this category (e.g. TD-FEM, TD-DG, network simulations), has increasingly been used in scientific and industrial domains in recent years and complements or supplements comparable methods on structured grids. With the results of this project, developers can with moderate effort extend existing source codes in high-level languages by domain-specific library and language elements. The intelligent compiler infrastructure uses domain knowledge to enable performance optimized, highly parallel execution on all relevant modern hardware architectures (Multicore, Manycore, GPU, FPGA), also in heterogeneous systems. Thus, the project offers to many HPC developers from science and industry an easy and sustainable path towards scaling usage of the most efficient current and future target architectures.
Paderborn University is the project consortium manager and involved in all work packages. The focus under the lead of Prof. Dr. Christian Plessl (High-Performance IT Systems) are the optimization and code generation for FPGAs as target platform, as well as the integration of communication end points on FPGAs. The main activity under the lead of Prof. Dr. Jens Förstner (Theoretical Electrical Engineering) are the requirement analysis and co-design from the nanophotonics perspective and the evaluation in this domain. Embedding the project into PC2 provides furthermore HPC-infrastructure, and additionally broad expertise and dissemination potential in scientific computing.
Funding: German Ministry for Education and Research, 01|H16005A
Program: 5th HPC Software Call
Runtime: 04/2017–03/2019
Website: TBA
PerficienCC - Performance and Efficiency in HPC with Custom Computing
To improve the energy efficiency of HPC systems they are increasingly augmented with hardware accelerators. The use of accelerators does however fall behind their fundamental performance and efficiency potential. In the PerficienCC project we work at closing this gap in cooperation with computational scientists that are customers of the HPC services at the Paderborn Center for Parallel Computing. We focus on application-specific hardware accelerators based on FPGAs. Through a tight cooperation of FPGA experts in our research group and developers of scientific codes at Paderborn University we will study the potential to accelerate important applications with FPGAs and we will port open-source scientific software to FPGAs. Additionally, we will provide generalized code with FPGA support as libraries to the community and will generate training material to educate computational scientists in this area. Our project aims at making FPGA technology more accessible and providing an empirical evaluation of the benefit of FPGAs for HPC and data center applications.
Funding: Germany Science Foundation
Program: Performance Engineering für wissenschaftliche Software
Runtime: 6/2017 (planned) - 5/2020
On-the-Fly Hardware Acceleration – subproject of the Collaborative Research Center 901 'On-the-Fly Computing'
The objective of CRC 901 – On-The-Fly Computing (OTF Computing) – is to develop techniques and processes for automatic on-the-fly configuration and provision of individual IT services out of base services that are available on world-wide markets. In addition to the configuration by special OTF service providers and the provision by what are called OTF Compute Centers, this involves developing methods for quality assurance and the protection of participating clients and providers, methods for the target-oriented further development of markets, and methods to support the interaction of the participants in dynamically changing markets.
Our contribution to the CRC 901 is to study whether on-the-fly compute centers that execute configured and composed IT services can optimize the execution by leveraging accelerators based on reconfigurable hardware. We assume that composed services will only be available as binaries, hence the process of offloading computations to hardware accelerators must operate on binary applications and needs to be completely transparent to the user. Our objective is to analyze, whether such a transparent optimization is feasible and if so, to determine the potential as well as the limitations of this approach.
Funding: German Science Foundation (DFG), collaborative research center SFB 901
Runtime: since 2012
Website: http://sfb901.uni-paderborn.de
SAVE – Self-Adaptive Virtualisation-Aware High-Performance/Low-Energy Heterogeneous System Architectures
The SAVE project investigates virtualization and heterogeneous computing in high-performance and embedded computing systems. The objective is to develop a runtime system and methods for migrating workload between heterogeneous resources (multi-core CPUs, Maxeler FPGA-Systems, and GPUs) in order to achieve an optimal use of resources. Additionally we will develop virtualization methods, that allow for operating GPUs and FPGAs in virtualized environments.
Our contribution to the project is to develop a runtime system based on a virtual machine that monitors applications during execution and analyzes their hotspots for estimating what could be gained in terms of performance and energy-efficiency when moving the workload to a different resource, e.g., from the CPU to the GPU. If the runtime system predicts that such a migration is beneficial the hotspot shall be automatically and on-the-fly extracted, optimized and compiled to the heterogeneous resource. Once the binary for the heterogeneous resource has been generated, the runtime system will migrate the execution of the hotspot from the original resource to the target resource.
Funding: European Commission, FP7 STREP Project, grant agreement 610996
Runtime: 2013–16
Website: http://www.fp7-save.eu
EPiCS – Engineering Proprioception in Computing Systems
EPiCS was a trans-national multi-disciplinary research project, which aimed at laying the foundation for engineering proprioceptive computing systems. Such systems collect and maintain information about their state and progress and reason about their behavior. This self-awareness allows the systems to autonomously adapt their behavior to changing conditions (self-expression). The concepts of self-awareness and self-expression are new to the domains of computing and networking; the successful transfer and development of these concepts will help create future heterogeneous and distributed systems capable of efficiently responding to a multitude of requirements with respect to functionality and flexibility, performance, resource usage and costs, reliability and safety, and security.
Our contribution to the EPiCS project was to study the architecture and operating systems for heterogeneous multi-core systems that are composed of CPUs, fixed function accelerators and reconfigurable accelerators. These heterogeneous multi-core systems allow for optimizing their behavior by migrating functionality between the heterogeneous computing resources for optimizing performance and efficiency goals.
Funding: European Commission, FP7 FET Integrated Project, grant agreement 257906
Runtime: 2010–14
Website: http://epics.uni-paderborn.de
ENHANCE – Enabling Heterogeneous Hardware Acceleration Using Novel Programming and Scheduling Models
ENHANCE was a research project carried out by German academic and industrial partners. The project aimed at a better integration and simplified usage of heterogeneous computing resources in high-performance computing systems. Heterogeneous computing systems contain multiple compute components, for example, multi-core processors, graphics processing units (GPUs), or field programmable gate arrays (FPGAs). While the use of compute accelerators promises significant improvements in performance and energy efficiency, developing applications for such heterogeneous systems raises challenges in programmability, performance estimation and scheduling. The ENHANCE project addressed these challenges by providing a compilation framework for porting applications to compute accelerators and a runtime system for scheduling tasks on heterogeneous resources.
Our contribution to the ENHANCE project was to develop a novel runtime system, that allows for time sharing and load-balancing of tasks, when executed on heterogeneous resources. To this end, we developed a new programming model that uses architecture independent checkpoints to allow migrating code between different compute resources. Further, we developed an extension to the Linux completely fair scheduler to allow for time-sharing of arbitrary compute resources and for migrating workload among compute resources to achieve a user defined objective, e.g., maximizing throughput, minimizing the average turn-around time, or maximizing energy efficiency.
Funding: German Federal Ministry of Education and Research (BMBF), grant agreement 01|H11004
Runtime: 2011–13
Website: http://www.enhance-project.de/en
Custom Computing Architectures for Nanophotonics
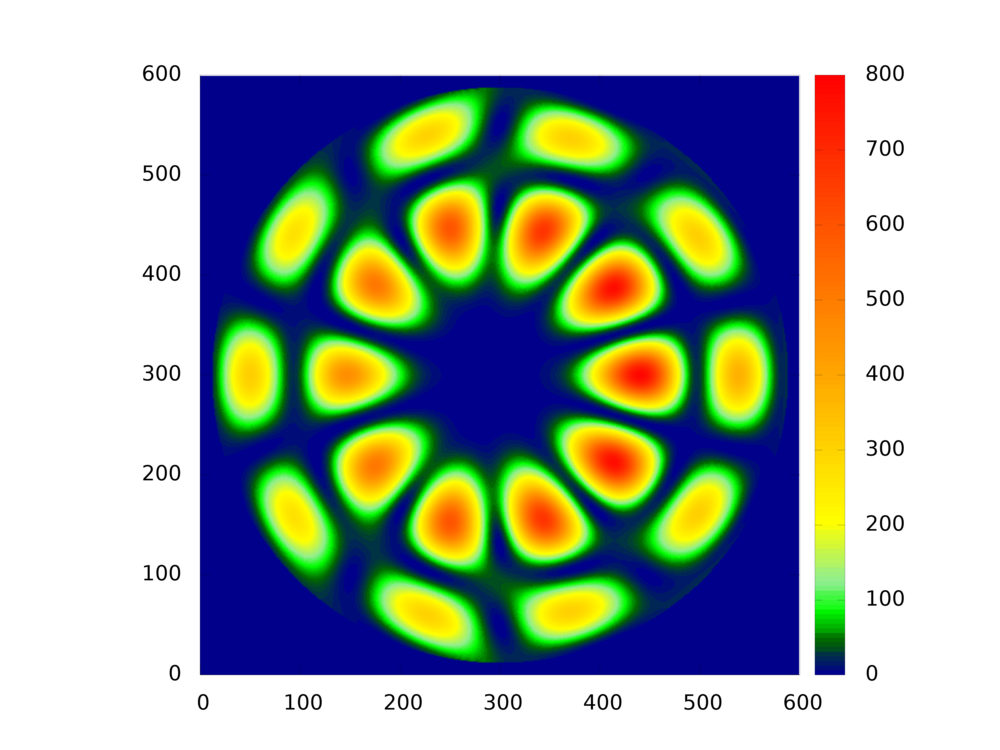
In this project we studied, how modern parallel and reconfigurable computer architectures, in particular FPGAs and GPUs, can be used effectively for simulations in theoretical physics. The target algorithm we studied is Yee's Finite-Difference Time Domain method for solving Maxwell's equations. This project that was initially funded by the Paderborn University Research Award, which was jointly awarded to Prof. Plessl and Prof. Förstner in 2009, was the basis for a longstanding collaboration with Prof. Förstner.
Initial funding: Paderborn University Research Award (2009)
Runtime: 2009–11
MM-RPU – A Multimode Reconfigurable Processing Unit
The project A Multimode Reconfigurable Processing Unit (initially funded by the Intel Microprocessor Technology Lab) studied how reconfigurable processing units can be integrated in microprocessors while maintaining a software-centric programming model. We have developed a high-level performance estimation framework that combines an analytic performance model (characterizing the hardware latencies, bandwidth, execution times) with application-specific data determined by static program analysis and traces generated by executing instrumented code. Using this framework we could perform a design space exploration for determining the optimal architecture for a given set of benchmark applications. Additionally, we could analyze the sensitivity of the results with respect to the parameters of the hardware architecture, e. g., communication bandwidth between CPU and reconfigurable processing unit.
Initial funding: Intel Microprocessor Technology Lab
Runtime: 2008–12